|
|
自从上一版本的VtubeKit在2023年12月份发布之后,已经过去半年时间,目前软件经历了底层的重构。
神经网络框架从tensorflow全部转换为pytorch。模型也采用了新的格式和架构,新的fsm模型同时支持训练和直播。
从本版起软件名和logo都发生更新:改名为XFaceKit。
-------------------------------------------------------------------------------
百度网盘下载链接(XFaceKit整合包):https://pan.baidu.com/s/1Evcqcc6tk2WAE3pkKAy4tQ?pwd=r9mq
预训练的模型和遮罩模型: https://pan.baidu.com/s/15kpsahg8ffL4VjhFU0D6ew?pwd=fv78
(备注:这些模型经过一些预训练,但是因为素材不充分,可根据自己的需求进一步补充素材继续训练。
fsm为换脸模型格式,vdf类似于df架构,viae类似于liae架构,dsn为全卷积架构。xseg和useg类型为遮罩模型)
-----------------------------------------------------------------------------
【系统要求】
只适用于Nvidia显卡的Windows系统
【版本包含程序】
Live-直播程序,Lab-素材处理程序,Train-模型训练程序
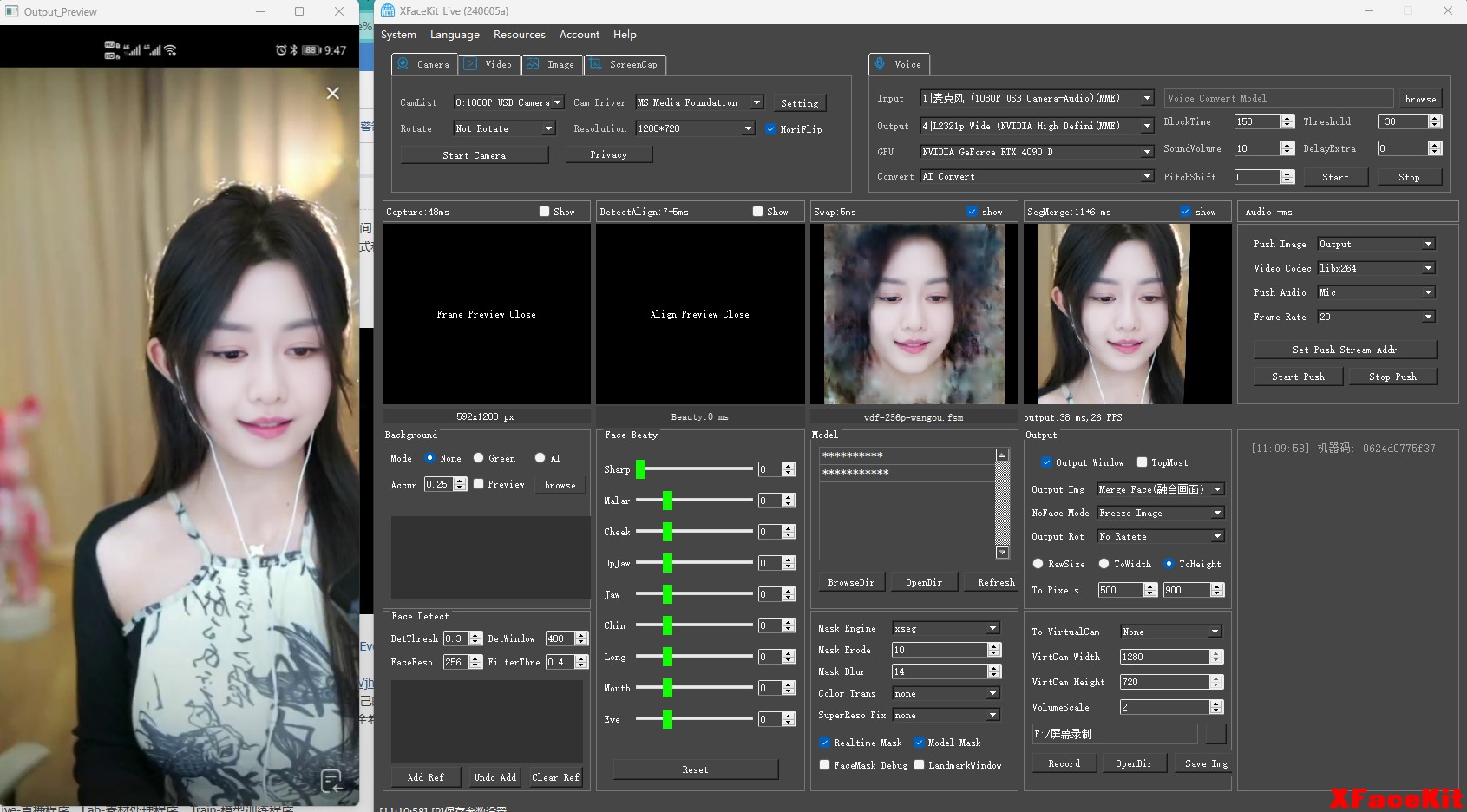
直播换脸工具(Live):
(1)帧率和速度: XFaceKit比deepfacelive的在高分辨率下运行速度更快,解决了Deepfacelive在高分辨率(大于1280*720P)时候帧率太低的问题。1920*1080p都可接近实时帧率
(2)调整脸型:可以通过拖动调整脸型。
(3)内置高精度分割模型实时分割人脸遮罩,遮罩没训练好的模型同样可以准确的处理遮挡物体。
(4)输入图像增加了实时截屏
(5)增加换声功能
(6)模型支持新的fsm文件格式,同时兼容deepfacelive的dfm格式模型。
(7)新增了换脸后超分修复功能,增加清晰度
(8)增加了人脸身份筛选,可以选择换脸的人脸对象
(9)可以把输出直接传送到OBS虚拟摄像头
3. 素材处理(Lab):
(1) 可以多源采集(视频文件、截屏、图片集、摄像头采集),一键自动切脸,同时完成标记和分割遮罩写入。
(2)多种批量文件重命名、素材移动筛选工具
(3)素材浏览器中可批量浏览遮罩特征点
(4)素材分析:自动分析生成素材角度分布图,浏览每个角度范围内的素材
(5)采用神经辐射场和3d变形模型结合对素材进行角度和表情增补
(6)升级的遮罩编辑器,可以自动生成可编辑多边形轨迹,提取五官区域,可以改变选取素材文件夹。
(7)素材超分辨率高清化处理、同时保留遮罩和特征点数据
(8)应用神经网络对模糊和低质量人脸筛选,比纯采用像素方差计算的传统方法准确率大幅度提升。
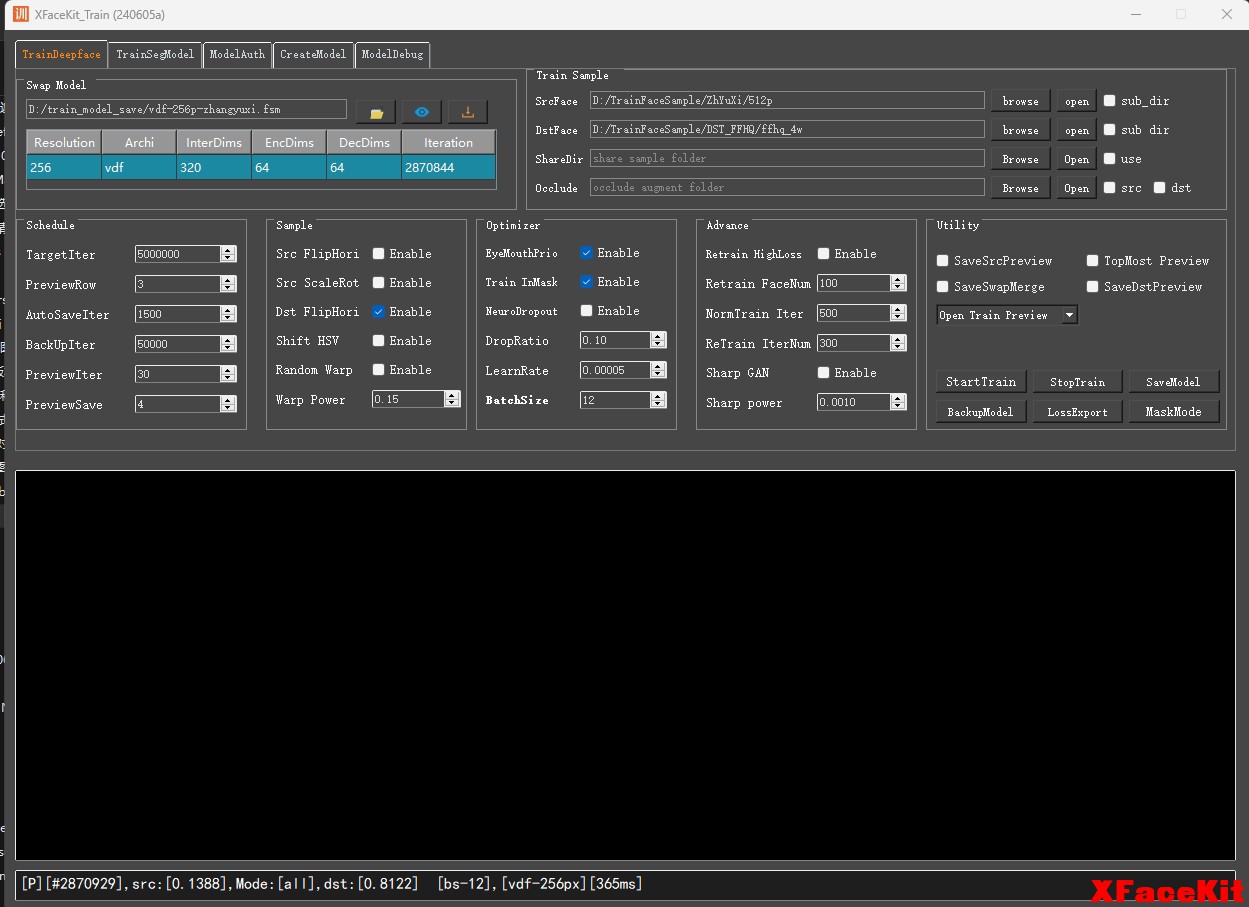
4. 模型训练(Train):
(1) 新的基于pytorch框架的模型结构和格,效率更高
(2)模型格式存储方式改变为单文件格式,换脸模型为fsm格式,遮罩分割模型为seg格式。 模型架构有多种架构可供选择。
(3)训练模型和直播模型通用,可以不用再单独导出直播模型。
(4) 训练换脸模型将不需要训练遮罩了,同时节约了模型计算量、显存、和硬盘存储空间
(5)模型预览都采取五列,高分辨也能多列预览,最后一列直接是融合后的预览更接近现实效果,不只是换脸后的图
(6)增加了src和dst共享素材。
(7)增加了遮挡物随即增强功能,可以随即添加遮挡增强素材多样性
(8)导出每个人脸的loss值,可以同时导出src和dst每张素材的loss值,导出csv文件,帮你筛选哪些图现在训练效果还不好。
|
|
评分
-
查看全部评分
|




 发表于 2024-6-5 17:18:50
发表于 2024-6-5 17:18:50



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 照妖镜
照妖镜